
Procyon® AIテキスト生成ベンチマーク 
ローカルLLM AIのパフォーマンステストの簡素化
AI LLMのパフォーマンステストは非常に複雑で時間がかかります。フルサイズのAIモデルでは、ダウンロードに大量のストレージスペースと帯域幅が必要になります。量子化、変換、および入力トークンのバリエーションなどの多くの変数があり、適切に設定されていないと、テストの信頼性が低下する可能性もあります。
Procyon AIテキスト生成ベンチマークは、複数のLLM AIモデルでAIパフォーマンスを繰り返しかつ一貫してテストする、よりコンパクトで簡単な方法を提供します。当社は、AIのソフトウェアおよびハードウェアの多くのリーダーと緊密に連携して、当社のベンチマークテストがお客様のシステム内のローカルAIアクセラレータのハードウェアを最大限に活用できるようにします。
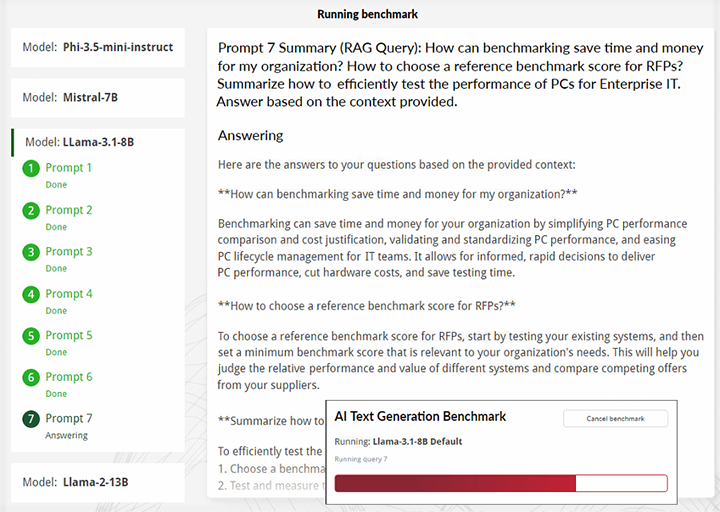
プロンプト7(RAGクエリ):ベンチマークによって、組織の時間とコストはどのように削減できますか?RFPの参照用ベンチマークスコアは、どのように選択しますか?企業IT向けPCのパフォーマンスを効率的にテストする方法をまとめます。提供されている文脈に基づいて回答してください。
結果とインサイト
業界リーダーからの入力に基づいて構築
- 業界をリードする主要AIベンダーからの入力に基づいて構築されており、次世代のローカルAIアクセラレータのハードウェアを最大限に活用します。
- RAG(検索拡張生成)クエリと非RAGクエリを使用して、複数の実際の使用事例をシミュレーションする7つのプロンプト
- 一貫性があり、繰り返し可能なワークロードを実行するように設計されており、一般的なAI LLMワークロードの変数を最小限に抑えます。
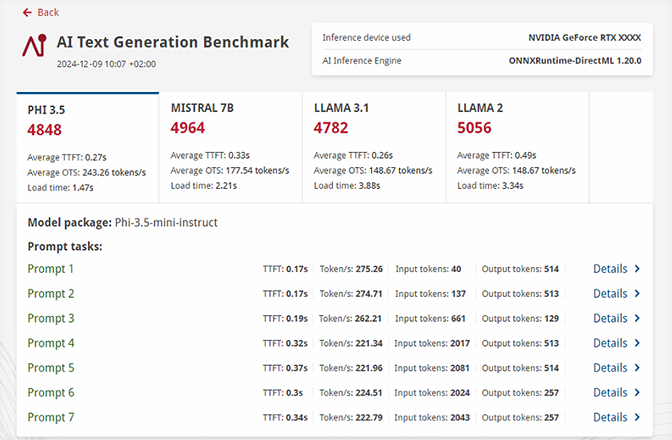
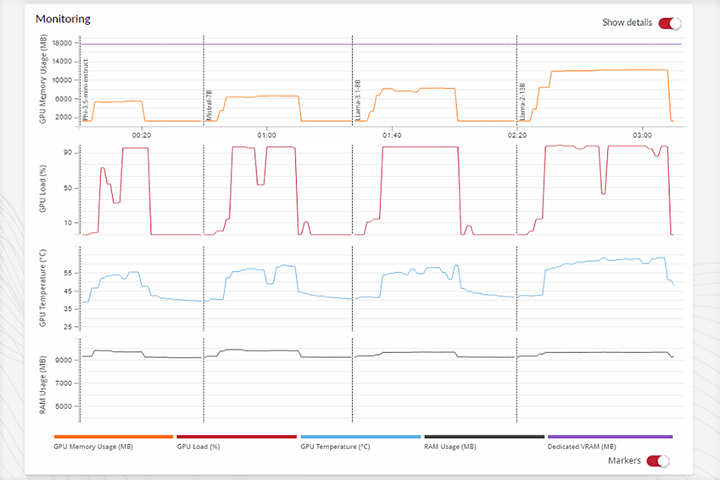
詳細な結果
- AIワークロード実行中のシステムリソースの使用状況に関する詳細なレポートを取得します。
- AIモデル全体を使用したテストと比較してインストールサイズが削減されました。
- デバイス間の結果を簡単に比較できるため、使用事例に最適なシステムの特定に役立ちます。
AIテストの簡素化
- パラメータサイズが異なる4つの業界標準AIモデルを使用して、簡単かつ迅速にテストします。
- ベンチマーク実行中に生成される応答をリアルタイムで確認
- ワンクリックで、サポートされているすべての推論エンジンで簡単にテスト、または好みに応じて設定します。
業界の専門知識を活かした開発
Procyonベンチマークは、業界、企業、報道機関向けに設計されており、プロフェッショナルユーザー向けに特別に作成されたテストと機能を備えています。ProcyonAIテキスト生成ベンチマークは、ULベンチマーク開発プログラム(BDP)で業界パートナーとともに設計・開発されました。BDPは、プログラムメンバーとの密接な連携により、適切かつ公平なベンチマークを作成することを目的としたUL Solutionsのイニシアチブです。
推論エンジンパフォーマンス
Procyon AIテキスト生成ベンチマークを使用すると、専用AI処理ハードウェアのパフォーマンスを測定し、負荷の高いAI画像生成ワークロードに基づくテストで推論エンジンの実装品質を検証できます。
プロフェッショナル向け設計
当社は、推論エンジン実装と専用ハードウェアの一般的なAIパフォーマンスを評価する独立した標準化ツールを必要とするエンジニアリングチームに、Procyon AI推論ベンチマークを作成しました。
高速で使いやすい
ベンチマークはインストールも実行も簡単で、複雑な設定は一切必要ありません。Procyonアプリケーションを使用、またはコマンドラインでベンチマークを実行します。ベンチマークスコアやチャートを表示、または詳細な結果ファイルをエクスポートしてさらに分析できます。
無償試用
試用リクエストサイトライセンス
見積もり 出版関係者向けライセンス- ProcyonAIテキスト生成ベンチマークの年間サイトライセンス。
- ユーザー数、無制限。
- デバイス台数、無制限。
- メールと電話による優先サポート。
システム要件
すべてのONNXモデル
ストレージ:18.25GB
すべてのOpenVINOモデル
ストレージ:15.45GB
Phi-3.5-mini
DirectMLを搭載したONNX
- 6GB VRAM(ディスクリートGPU)
- 16GBシステムRAM(iGPU)
- ストレージ:2.15GB
Intel OpenVINO
- 4GB VRAM(ディスクリートGPU)
- 16GBシステムRAM(iGPU)
- ストレージ:1.84GB
Llama-3.1-8B
DirectMLを搭載したONNX
- 8GB VRAM(ディスクリートGPU)
- 32GBシステムRAM(iGPU)
- ストレージ:5.37GB
Intel OpenVINO
- 8GB VRAM(ディスクリートGPU)
- 32GBシステムRAM(iGPU)
- ストレージ:3.88GB
Mistral-7B
DirectMLを搭載したONNX
- 8GB VRAM(ディスクリートGPU)
- 32GBシステムRAM(iGPU)
- ストレージ:3.69GB
Intel OpenVINO
- 8GB VRAM(ディスクリートGPU)
- 32GBシステムRAM(iGPU)
- ストレージ:3.48GB
Llama-2-13B
DirectMLを搭載したONNX
- 12GB VRAM(ディスクリートGPU)
- 32GBシステムRAM(iGPU)
- ストレージ:7.04GB
Intel OpenVINO
- 10GB VRAM(ディスクリートGPU)
- 32GBシステムRAM(iGPU)
- ストレージ:6.25GB
サポート
最新1.0.82.0 | 2024年12月9日
言語
- 英語
- ドイツ語
- 日本語
- ポルトガル語(ブラジル)
- 簡体字中国語
- スペイン語